
AI Agents: Multi-Agent Systems with Hierarchical Planning – A Practical Guide to LLM-Orchestrated Swarms
Artificial intelligence is no longer a single monolithic model that answers every question. Instead, the most promising frontier lies in multi-agent systems (MAS) where specialized AI agents collaborate, negotiate, and reason together to tackle tasks that are too complex for a lone language model. In this post we explore how hierarchical planning, tool use, memory hierarchies, and conflict-resolution mechanisms can be woven together using popular frameworks such as AutoGen, CrewAI, and LangGraph. Whether you are building a code-generation pipeline, optimizing a supply-chain network, or experimenting with self-improving agents, the concepts and concrete patterns below will give you a solid foundation.
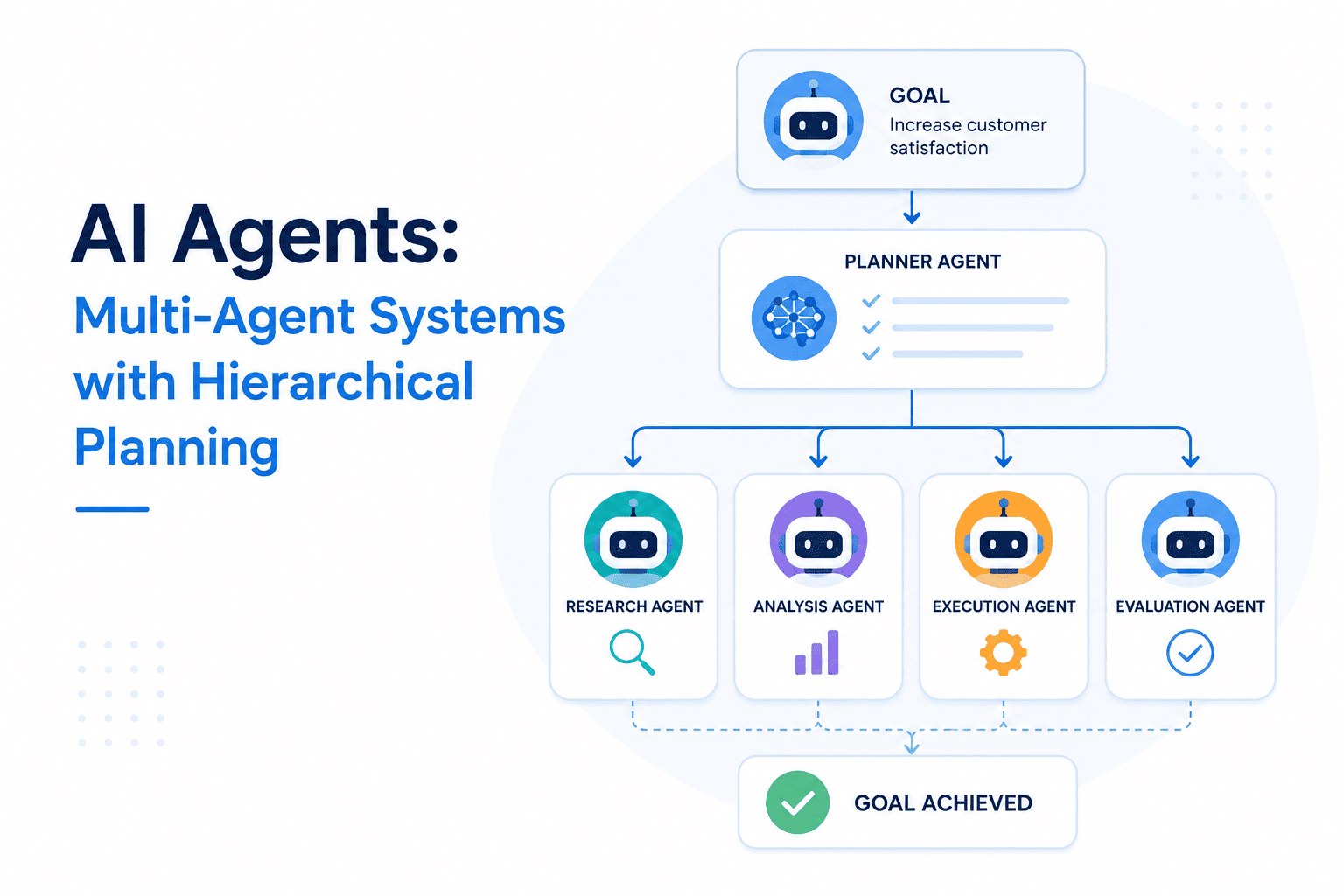
Why Hierarchical Planning Matters for AI Agents 🧠
When a single LLM is asked to solve a long-horizon problem—say, “write a production-ready microservice that processes real-time sensor data and feeds results into a cloud dashboard”—the model often drifts, hallucinates, or forgets intermediate constraints. Hierarchical decomposition breaks the overarching goal into manageable sub-goals, each assigned to a dedicated agent or sub-team.
- LLM planners act as the “project manager.” They receive the high-level objective, generate a structured plan (often a tree or DAG), and delegate leaf nodes to worker agents.
- Each worker can further decompose its assignment, creating a recursive hierarchy that mirrors how human teams split work into milestones, sprints, and tasks.
- The planner continuously monitors progress, re-plans when failures occur, and injects corrective actions—exactly the feedback loop needed for robust, long-horizon reasoning.
This approach not only curbs hallucination propagation (errors stay localized) but also enables parallelism: multiple agents can work on independent branches simultaneously, dramatically reducing wall-clock time.
Core Building Blocks: ReAct vs. Plan-and-Execute ⚙️
| Paradigm | Core Loop | Strengths | Typical Use-Case |
|---|---|---|---|
| ReAct (Reason-+-Act) | Thought → Action → Observation → (repeat) | Tight coupling of reasoning and tool use; excellent for interactive, step-by-step tasks like debugging code or answering multi-hop questions. | Interactive coding assistants, data-analysis notebooks. |
| Plan-and-Execute | Planner creates a full or partial plan → Executor carries out actions → Planner revises plan based on outcomes | Clear separation of strategic thinking from low-level execution; easier to enforce hierarchies and inject memory. | Batch workflows, supply-chain optimization, large-scale code generation. |
In practice, many systems hybridize both: a high-level planner uses Plan-and-Execute to outline milestones, while each milestone is tackled by a ReAct-style agent that can call tools, fetch external data, and self-correct on the fly.
Tool Use & Memory Hierarchies 🗂️
Agents become truly powerful when they can invoke external tools (code compilers, APIs, simulators) and retain context across multiple interactions.
1. Tool-Use Layer
- Each agent exposes a toolbox:
python,jupyter,docker build(code execution)- API calls (REST, GraphQL, database queries)
- Domain-specific simulators (network traffic, manufacturing line)
- The planner can annotate a sub-goal with required tools, ensuring the executor knows exactly what to call.
2. Memory Hierarchy
- Working Memory (short-term): Holds the current observation, recent thoughts, and tool outputs. Implemented as the LLM’s context window plus a short-term cache.
- Episodic Memory (medium-term): Stores completed sub-tasks, success/failure flags, and lessons learned. Often realized with a vector store (FAISS, Pinecone) enabling similarity-based retrieval.
- Semantic Memory (long-term): Encodes domain knowledge, best practices, and reusable code snippets. This can be a fine-tuned LLM or a retrieval-augmented generation (RAG) corpus.
By routing queries through the appropriate memory tier, agents avoid re-reasoning from scratch and can leverage past successes—critical for self-improvement loops.
Conflict Resolution in Agent Swarms ⚠️
When multiple agents pursue overlapping goals, conflicts arise: competing resource allocations, contradictory code changes, or divergent optimization objectives. Effective MAS must detect, negotiate, and resolve these tensions.
- Negotiation Protocols – Inspired by contract-net or auction mechanisms, agents propose bids (e.g., time, compute, quality) for a task. The planner selects the winning bid, and losers either retreat or propose alternatives.
- Constraint-Based Reasoning – Each agent maintains a set of hard and soft constraints (e.g., latency < 100ms, memory < 2GB). A central constraint solver (or a distributed consensus algorithm) checks feasibility and suggests trade-offs.
- Version-Controlled Artifacts – For code generation, agents write to isolated branches; a merge-bot runs automated tests and static analysis before allowing a commit. Conflicts are flagged as merge-requests for human or LLM-mediated resolution.
- Hallucination Dampening – By confining hallucinations to local tool outputs and validating them against executors (unit tests, simulation results), errors rarely propagate up the hierarchy. When they do, the planner can trigger a re-plan that isolates the faulty branch.
Showcase: Supply-Chain Optimization via Agent Negotiation 🏭
Consider a global electronics manufacturer that wants to minimize total landed cost while respecting service-level agreements. The problem naturally decomposes:
- Strategic Planner (LLM) – Generates a high-level plan: determine optimal inventory levels, select suppliers, schedule shipments.
- Tactical Agents – Each responsible for a region or product line. They run re-act loops invoking optimization solvers (linear programming, reinforcement learning) and external ERP APIs to propose concrete policies.
- Negotiation Layer – Agents exchange proposals on shared resources (e.g., port capacity, truck fleets). Using a simple auction, the planner awards capacity to the highest-value bid, while losers adjust their local plans.
- Feedback Loop – After execution, observed delays or excess inventory are logged into episodic memory; the planner updates its demand forecasts, triggering a new planning cycle.
The result is a self-tuning supply chain where the LLM planner steers strategy, agents handle tactical detail, and negotiation ensures global coherence without a central controller dictating every move.
AutoGen, CrewAI, and LangGraph – Frameworks that Make It Real 🛠️
| Framework | Core Idea | Hierarchical Support | Tool Integration | Typical Strength |
|---|---|---|---|---|
| AutoGen (Microsoft) | Conversable agents that can generate code, critique, and execute. | Supports nested agent groups; a “group chat” can act as a planner. | Built-in code execution, function calling, and external API wrappers. | Rapid prototyping of LLM-driven coding swarms. |
| CrewAI | Role-based agents (e.g., researcher, writer, reviewer) that collaborate on tasks. | Explicit “process” definitions enable hierarchical pipelines (research → draft → review). | Plug-in tools via LangChain; easy to add custom functions. | Clear separation of concerns; great for content generation pipelines. |
| LangGraph | Graph-based orchestration where nodes are agents or tools, edges represent data/control flow. | Naturally expresses DAGs; sub-graphs can be collapsed into higher-level nodes. | Any LangChain-compatible tool can be a node; state is passed along edges. | Fine-grained control over execution order, ideal for complex workflows like multi-step code generation. |
Practical tip: Start with AutoGen for quick experimentation (its conversational agents already implement ReAct). As your workflow stabilizes, migrate critical sub-graphs to LangGraph to gain explicit control over planning vs. execution layers, and use CrewAI when you need clearly delineated role responsibilities (e.g., a “code reviewer” agent that enforces style guides).
Mitigating Hallucination Propagation in Long-Horizon Tasks 🛡️
Even with hierarchical planning, errors can accumulate. Proven mitigation strategies include:
- Tool-Backed Validation – Every LLM-generated claim (e.g., “function X returns Y”) is immediately checked against a unit test, type checker, or simulation. Failures trigger an immediate re-plan.
- Confidence Scoring – Agents attach a confidence metric to their outputs; low-confidence results are flagged for additional verification or human review.
- Iterative Refine-Loop – After an initial pass, a separate “critic” agent reviews the output, suggests improvements, and the planner incorporates those suggestions in the next iteration.
- Synthetic Data Loops for Self-Improvement – Agents generate synthetic training examples from successful executions (e.g., correct code snippets, valid plans). These examples are stored in semantic memory and used to fine-tune the planner or worker LLMs, steadily reducing hallucination rates over time.
Self-Improving Agents via Synthetic Data Loops 🔄
The concept is simple yet powerful: agents teach themselves by converting their own successful experiences into training data.
- Execution Phase – A swarm completes a task (e.g., generates a bug-free microservice).
- Data Extraction – The planner logs the goal, sub-goal decomposition, tool calls, observations, and final artifact. Successful traces are labeled as positive examples.
- Synthesis – Using a language model, we augment the trace with variations (different variable names, alternative tool orders) to create a richer dataset.
- Fine-Tuning – The planner LLM (or a dedicated “policy” model) is fine-tuned on this dataset, improving its ability to generate accurate hierarchical plans.
- Deployment – The updated model is redeployed, and the cycle repeats.
Over multiple iterations, the swarm exhibits reduced planning errors, better tool selection, and higher success rates on novel but related tasks—a hallmark of truly autonomous AI systems.
Putting It All Together: A Sample Workflow for Code Generation 💻
Imagine you want to generate a full-stack web application that meets performance, security, and scalability requirements.
- High-Level Planner (LLM) – Decomposes the request into: API design, database schema, frontend UI, DevOps pipeline.
- Sub-Planner per Module – Each sub-planner further splits its module (e.g., API design → endpoints, authentication, rate limiting).
- Worker Agents (ReAct style) – For each leaf node, an agent writes code, runs linters/unit tests, observes failures, and iterates. Tools include
git,pytest,docker build. - Memory – Working memory holds the current code snippet; episodic memory stores past successful snippets (e.g., “JWT auth middleware”); semantic memory holds language-specific best-practice libraries.
- Negotiation – If two agents propose conflicting versions of a shared library version, they negotiate via a simple bid (based on compatibility score).
- Hallucination Check – Generated code is automatically compiled and tested; any failure triggers a re-plan at the offending node.
- Self-Improvement Loop – Successful code traces are fed back into the planner’s fine-tuning pipeline, steadily improving the quality of generated scaffolds.
The result is a robust, self-correcting software factory that can adapt to new requirements with minimal human intervention.
Final Thoughts 💡
Hierarchical multi-agent systems represent a pragmatic path toward reliable, scalable AI that can handle the messy, open-ended problems of the real world. By combining LLM-driven planning, ReAct/Plan-and-Execute reasoning, rich tool use, structured memory, and principled conflict resolution, developers can construct agent swarms that not only perform complex tasks today but also learn to do them better tomorrow.
Whether you are optimizing a supply chain, generating production-grade code, or experimenting with self-improving AI, the frameworks and patterns discussed here give you a battle-tested roadmap. Start small—prototype a two-level hierarchy with AutoGen—and let the swarm’s emergent intelligence guide your next iteration.
Happy building, and may your agents always find the optimal path!




