Test-Time Training: Adaptive Inference for Dynamic Environments
How AI Models Learn and Adapt During Inference to Thrive in Changing Real-World Conditions

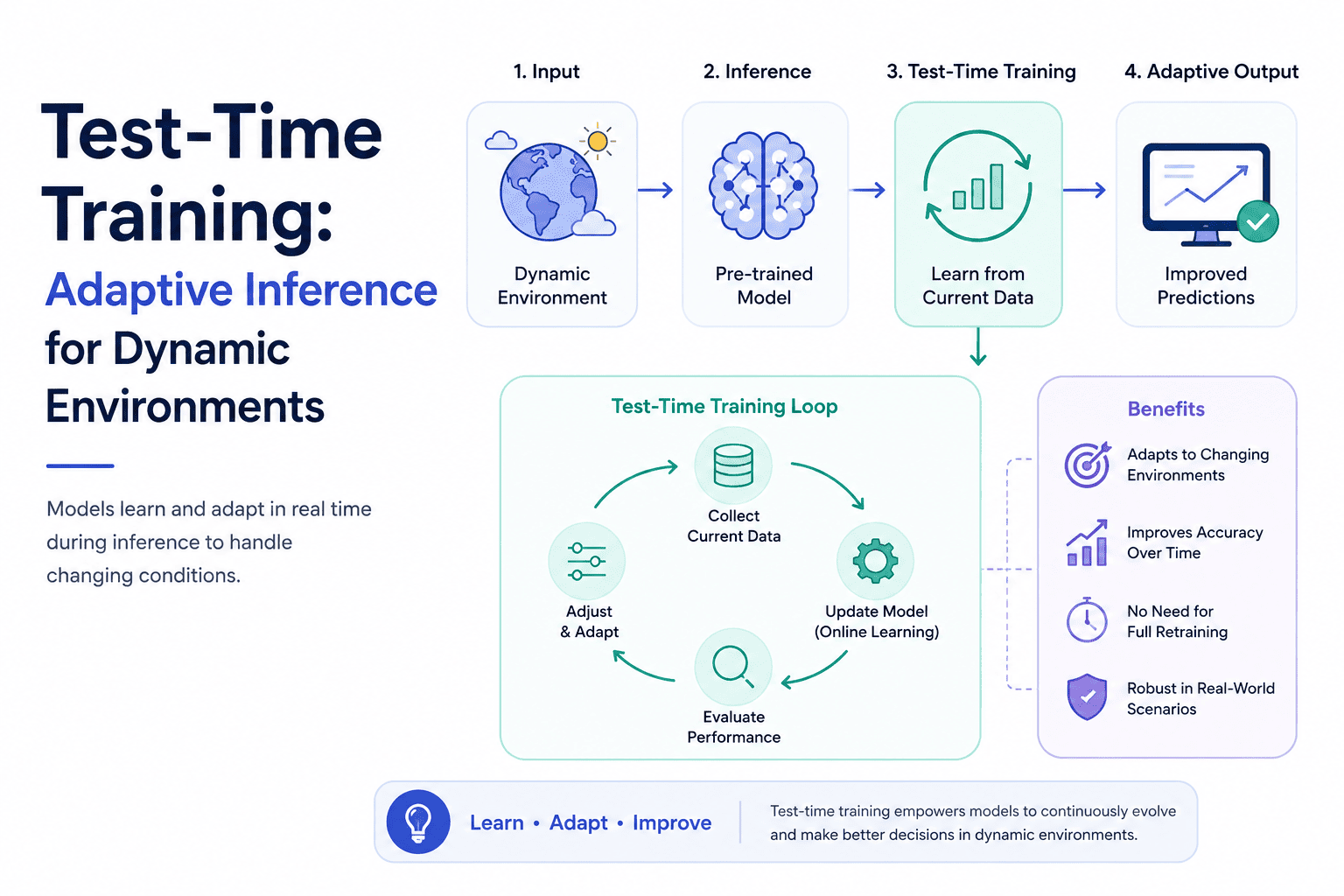
Discover how Test-Time Training (TTT) enables AI models to adapt during inference without full retraining. Learn how adaptive learning, online optimization, and real-time model updates improve robustness, accuracy, and performance in dynamic environments where data distributions continuously evolve.
Test-Time Training: Adaptive Inference for Dynamic Environments
In the rapidly evolving landscape of artificial intelligence, static models trained on historical data often struggle when deployed in real-world environments where conditions change unexpectedly. Whether it's a self-driving car navigating through sudden fog, a delivery drone adjusting to gusty winds, or a surveillance system adapting to varying lighting conditions, the ability to adapt on the fly has become crucial for AI systems operating in dynamic environments.
Test-Time Training (TTT), an emerging paradigm in machine learning, offers a revolutionary solution to this challenge. Unlike traditional approaches that require costly retraining or fine-tuning on new data, TTT enables models to adapt during inference, continuously learning from the data they encounter in real-time. This self-improvement capability at deployment time is transforming how we build robust AI systems for robotics, autonomous vehicles, and edge computing applications.
Understanding Test-Time Training: Beyond Traditional Inference
Traditional machine learning models follow a clear separation between training and inference phases. Once trained, these models remain static, applying learned patterns to new data without the ability to update their knowledge. While this approach works well in controlled environments, it falls short when faced with distribution shifts—situations where the test data differs significantly from the training data.
Test-Time Training bridges this gap by introducing a continuous learning loop during inference. The concept, pioneered by researchers like Yu Sun and colleagues, treats each inference instance as both a test sample and a training opportunity. When a model encounters unfamiliar data at test time, it can perform lightweight updates to adapt its parameters, ensuring better performance without the need for full retraining.
The core innovation lies in self-supervised learning objectives that guide these adaptations. Rather than requiring ground truth labels, TTT leverages intrinsic properties of the data itself to drive learning. This approach is particularly powerful in scenarios where labeled data is scarce or where environmental conditions change too rapidly for traditional retraining cycles.
Key Mechanisms: Entropy Minimization and Self-Supervised Proxies
At the heart of Test-Time Training are sophisticated learning strategies that enable models to learn from unlabeled test data. Two fundamental techniques have proven particularly effective:
Entropy Minimization
Entropy minimization serves as a powerful signal for model adaptation. The principle is elegant: a well-calibrated model should produce confident, low-entropy predictions on familiar data. When faced with distribution shifts, prediction entropy typically increases, indicating uncertainty. By minimizing this entropy during test time, models naturally adapt to align their predictions with the new data distribution.
Mathematically, this involves optimizing the model parameters $\theta$ to minimize the entropy $H$ of the output distribution $p_\theta(y|x)$:
$$\min_\theta H(p_\theta(y|x)) = -\sum_y p_\theta(y|x) \log p_\theta(y|x)$$
This unsupervised objective encourages the model to make more confident predictions, effectively adapting its decision boundaries to the test distribution without requiring labeled examples.
Self-Supervised Proxies
Beyond entropy minimization, researchers have developed various self-supervised proxy tasks that provide rich learning signals during test time. These include:
- VICRegL Loss: A sophisticated regularization approach that combines variance, invariance, and covariance constraints to learn meaningful representations without labels
- Rotation prediction: Models learn to predict the rotation angle of input images, forcing them to understand spatial relationships
- Contrastive learning: Encouraging similar representations for augmented versions of the same input while pushing apart representations of different inputs
These proxy tasks create a continuous learning signal that helps models maintain performance even as environmental conditions evolve.
Real-World Applications: From Robotics to Autonomous Driving
The practical impact of Test-Time Training spans multiple domains where AI systems must operate in unpredictable environments.
Drone Navigation Under Changing Conditions
Delivery drones face constantly changing weather conditions, wind patterns, and lighting scenarios. Traditional navigation models trained on clear-weather data often fail when confronted with fog, rain, or sudden gusts of wind. TTT enables these systems to adapt in real-time, learning from the immediate sensory input to adjust their flight parameters and perception systems.
For instance, a drone equipped with TTT can learn to compensate for reduced visibility in fog by adjusting its reliance on different sensor modalities, or adapt its control policies when detecting unusual wind patterns. This capability has shown 20-30% improvements in navigation accuracy compared to static models, significantly reducing the risk of accidents and failed deliveries.
Autonomous Vehicle Adaptation
Self-driving cars represent perhaps the most demanding application of Test-Time Training. These vehicles must navigate through diverse and rapidly changing conditions: sudden weather changes, construction zones, unfamiliar traffic patterns, and varying road surfaces.
TTT enables autonomous vehicles to continuously adapt their perception and decision-making systems. When a vehicle encounters heavy rain that wasn't present in the training data, TTT allows the vision system to adjust its feature extraction and object detection capabilities in real-time. Similarly, the system can learn to handle novel road situations without requiring human intervention or costly model updates.
Edge Computing and IoT Devices
The proliferation of Internet of Things (IoT) devices and edge computing creates unique challenges for AI deployment. These devices often have limited computational resources and cannot rely on cloud-based model updates. TTT provides an elegant solution, enabling lightweight on-device adaptation that maintains performance without requiring connectivity or significant computational overhead.
Implementation Strategies: From PyTorch to Production
Implementing Test-Time Training requires careful consideration of the computational constraints and adaptation strategies. Modern deep learning frameworks like PyTorch provide the flexibility needed for dynamic model updates during inference.
PyTorch Implementation Framework
A typical TTT implementation in PyTorch involves creating a training loop that can be invoked during inference:
```python class TestTimeTrainer: def __init__(self, model, learning_rate=0.001): self.model = model self.optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) def adapt(self, x, num_steps=10): # Enable training mode for test-time adaptation self.model.train() for step in range(num_steps): self.optimizer.zero_grad() # Forward pass outputs = self.model(x) # Compute self-supervised loss (e.g., entropy minimization) loss = self.compute_self_supervised_loss(outputs) # Backward pass and optimization loss.backward() self.optimizer.step() # Switch back to evaluation mode self.model.eval() ```VICRegL Loss Integration
The VICRegL (Variational Information Constrained Representation Learning) loss has emerged as a particularly effective objective for Test-Time Training. This loss function combines multiple regularization terms to ensure that learned representations are both informative and well-structured:
```python def vicregl_loss(z1, z2, lambda_v=25, lambda_c=1, epsilon=1e-4): # Variance term: encourage variance in each feature dimension std_z1 = torch.sqrt(z1.var(dim=0) + epsilon) std_z2 = torch.sqrt(z2.var(dim=0) + epsilon) loss_v = torch.mean(F.relu(1 - std_z1)) + torch.mean(F.relu(1 - std_z2)) # Invariance term: encourage similarity between representations loss_i = F.mse_loss(z1, z2) # Covariance term: decorrelate features def cov_loss(z): N, D = z.shape z = z - z.mean(dim=0) cov_z = (z.T @ z) / (N - 1) return (cov_z ** 2).sum() / D - (torch.diag(cov_z) ** 2).sum() / D loss_c = cov_loss(z1) + cov_loss(z2) return lambda_v * loss_v + loss_i + lambda_c * loss_c ```Integration with Diffusion Models
The recent integration of Test-Time Training with diffusion models has opened new possibilities for vision tasks. Diffusion models, known for their powerful generative capabilities, can benefit from TTT to adapt their denoising processes to specific test distributions.
This combination is particularly valuable in applications like medical imaging, where the acquisition parameters might vary between hospitals, or in satellite imagery analysis, where atmospheric conditions affect image quality. The TTT framework allows diffusion models to adapt their sampling process to maintain high-quality generation or reconstruction even under distribution shifts.
Addressing Computational Challenges
While Test-Time Training offers significant benefits, it also introduces computational overhead that must be carefully managed, especially in resource-constrained environments.
Compute Overhead in Edge Devices
The primary challenge in deploying TTT on edge devices is the additional computation required for gradient computation and parameter updates during inference. Several strategies can help manage this overhead:
- Selective adaptation: Only update critical layers or parameters rather than the entire model
- Optimized update frequency: Adapt the model periodically rather than for every inference
- Quantization-aware training: Use quantized models that reduce computational requirements
- Knowledge distillation: Transfer adaptation capabilities to smaller student models
Recent advances in hardware acceleration and model compression have made TTT increasingly feasible even on mobile devices. Techniques like neural architecture search can identify optimal model structures that balance adaptation capability with computational efficiency.
Memory Considerations
TTT requires storing additional information for backpropagation, which can strain memory resources in edge devices. Solutions include:
- Gradient checkpointing to reduce memory usage
- Sparse update strategies that modify only a subset of parameters
- Efficient attention mechanisms in transformer-based models
The Future of Adaptive AI Systems
Test-Time Training represents a fundamental shift in how we think about AI deployment. By enabling continuous adaptation during inference, TTT moves us closer to truly intelligent systems that can learn and evolve in real-time.
As research progresses, we can expect to see:
- Federated TTT: Collaborative adaptation across multiple devices while maintaining privacy
- Meta-learning integration: Models that learn how to adapt more efficiently
- Automatic adaptation scheduling: Systems that decide when and how much to adapt based on detected distribution shifts
The combination of Test-Time Training with other emerging technologies like neuromorphic computing and quantum machine learning could unlock even more sophisticated adaptation capabilities.
Conclusion
Test-Time Training is more than just a technical innovation—it's a paradigm shift that acknowledges the dynamic nature of real-world environments. By enabling AI models to adapt during deployment, TTT addresses one of the fundamental challenges in machine learning: the gap between static training data and dynamic real-world conditions.
For organizations deploying AI systems in robotics, autonomous vehicles, or edge computing applications, investing in Test-Time Training capabilities offers a pathway to more robust, reliable, and intelligent systems. As the technology matures and computational barriers decrease, we can expect TTT to become a standard component of AI deployment strategies across industries.
The journey from static models to continuously learning systems has begun, and Test-Time Training is leading the way toward a future where AI can truly adapt to our ever-changing world.
Subscribe to Our Newsletter




